Place 24/7 Eyes On Your Partners and Vendor Services
I’m going to start off by sharing a recent story about a vendor and my hope is that by reading this article, you’ll start to do the same if you’re not already.
Many months ago, my office signed up for a unique Customer Relationship Management (CRM) service. The SaaS solution involves an intuitive client portal where sales staff can make focused and tailored landing pages and content for prospects. After meeting the company’s owner and rolling out the service, I hopped on my Nagios XI server and, through the use of the “Monitor A Website” wizard, entered in the CRM site’s public addresses and had almost every bit of necessary data needed. With just a few clicks, I was able to see on a minute by minute basis how this company’s CRM client portal website was performing, when the SSL and domain names were going to expire, what has changed on the site and when, etc. This is data that, as a business owner, you would expect to monitor on your own services and content, so my question to you is why not also monitor the services you are paying for?
Let’s step forward a bit in time to answer that question:
It was the morning of Christmas Eve and our office was closed for the day. I received an alert on my phone from my Nagios XI server telling me that one of the services I was monitoring was in a critical DOWN state. This alert was about something I don’t own or even have control of… It was the CRM website.
I hopped on LinkedIn and sent a message to the website’s owner after about 30 minutes had passed. My first thought was to simply disregard the alert as, after all, it was Christmas Eve and heck–it may even be a great time to perform site maintenance since there’s a good chance very few people are using the site! Still, I thought to myself, “If this were my site and company, I would probably want to know–even if the data is repetitive.”
Sure enough, he responded promptly and, to his surprise, identified a frozen AWS server to be the culprit. Because of how exactly the AWS instance froze, Amazon’s own monitoring service failed to detect an outage or trigger an action and he was left in the dark. After discussing the event later in the week when business hours resumed, it was clear that there were some amazing opportunities here.
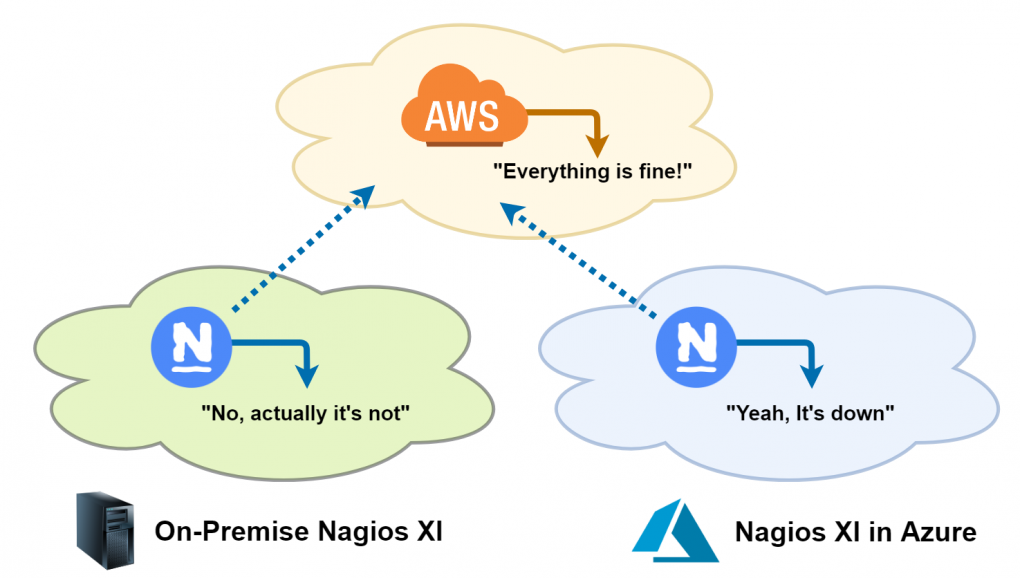
I strongly believe the powers of any network engineer or system administrator depend not only on what they have in their toolbox, but how they arrange it. Blocking or simply not recording performance data to begin with is not only a risk, but is too affordable today to not make verbosity a standard! The key is filtering and organizing the data so you can immediately see it in your toolbox while troubleshooting. What was the incentive for me to log into my Nagios XI server and set up a watchdog on this CRM website? I don’t own it. I’m not their IT guy. But when the services stop running, here’s what I have in my toolbox:
- Keep Vendors Honest
- Keeping an eye on all vendor client portals, applications, and services sets a precedence both internally and externally. It establishes that you are more than the SLA contract you sign.
- If a vendor or SaaS supplier is suggesting to you that their services were, in fact, functional, the data you produce and counter from multiple lenses plays a significant role in resolution.
- In my example, AWS failed to do its job of reporting and automating actions. A single source of truth is a liability. Having a second and third set of eyes in every direction is critical. At the very least, it’s better to be overwhelmed than not informed at all. That said, there are many ways to reduce being overwhelmed and it all begins with properly organizing your monitoring solutions.
- Stay on top of the responsibility food chain
- If you’re a system administrator, DevOps, or network engineer and your desk periodically has random gifts left on it like power cords or obscure old software/hardware found around the office, it indicates that you are the go-to for all things computers and technology. Optically speaking, this means if a cloud solution goes down, everyone is looking at you. Monitoring all of these services goes a long way in staying ahead of messaging and service tickets.
- Troubleshoot from another important lens
- Every metric matters when troubleshooting. Establishing the “is it me or them” is often times the best place to start. For example, if you’re troubleshooting a VoIP issue, it may make sense to monitor the IP or FDQN provided by your SIP trunk/provider to establish the necessary divide between on-premise, multi-location, or cloud challenges. You can reduce the time spent ruling out internal factors if the first alert you see indicates that the vendor is having difficulties.
- Office 365 Exchange tests every X minutes, file/folder checking on cloud storage providers, jitter/latency/MOS tests on your cloud VoIP provider trunks, synthetic login and behavioral tests on service portals & websites, HTTP status checks on partner billing sites, etc — All of this exists and is valuable data to have and call upon!
- Provides data and reports that may persuade you to seek other options
- “This service is always down…” Is it? Run a few reports against the service with a few clicks of a button to determine if that’s really the case. If it is, awesome — You now have a clear path to upgrade or switch to a different vendor. If it’s not, bummer — You’re now about to begin auditing and determining what to do about your current infrastructure. Either way, you have a more accurate direction to navigate towards.
The takeaway here is to look at business infrastructure beyond the closet and beyond the cloud services you’re directly responsible for. We are all operating in hybrid environments and each vendor introduces many additional mixed dependencies and undocumented points of failure. A single source of truth was never satisfactory before the cloud, so the goal of any IT department should be to monitor every tool that is being used no matter where it resides.